- AIクラッチ Newsletter 世界のAI情報を最速で発信
- Posts
- Geminiがマルチモーダル対応へ!ChatGPT Deep Researchの入門ガイドも徹底解説✨
Geminiがマルチモーダル対応へ!ChatGPT Deep Researchの入門ガイドも徹底解説✨
AIクラッチ News
March 18, 2025
Geminiがマルチモーダル対応へ!
さらに:ChatGPT Deep Researchの入門ガイドをゼロから学ぶ方法✨
⏱️ 読了目安時間:4分以内
Alphabetが「Gemma 3」を発表したばかりなのに、もう次の動き? そう、今回は「Gemini」自体がマルチモーダル画像生成機能を搭載したことで業界がざわついています。画像生成だけでなく、細かい部分編集やワードの埋め込みなども可能。
あわせて、ChatGPTの『Deep Research』をまだ使ったことがない人向けに、ゼロからリサーチを始める手順をご紹介。4分で最新のAIテクをキャッチアップしましょう!✨
今日のAI

1. Cohereが「超効率」LLMを発表しGemma 3に対抗
GoogleのGemma 3が出て数日、Cohereも新モデル「Command A」をリリース。
DeepSeekやOpenAIの最新モデル並みの性能を「わずか2枚のNvidia GPU」で実現と謳う。
スモールビジネス向けにコストを抑えた運用が可能に。
2. 自動生成の広告がリアルすぎる:CaptionsのMirage機能
NYCのCaptionsがAIインフルエンサー生成機能「Mirage」を公開。
音声またはテキストをアップロードすれば、体の動きや微細な表情もリアルに再現し、まるで本物のインフルエンサーが宣伝する動画を作成できる。
競合ツールと比べて自然な身体動作とマイクロ表情が特徴。
3. Nous Researchが“ハイブリッド”LLM「DeepHermes」を予告
検閲フリーで知られるNousが、新モデルDeepHermesの3B/24B版をプレビューリリース。
チェーン・オブ・ソート(論理的思考)とクイックレスポンス(即時応答)を1つのインターフェースで切り替えられる世界初のモデルと主張。
「クローズドソースのモデルと異なり、推論プロセスを完全に表示するモードも備える」とのこと。
フロンティアから
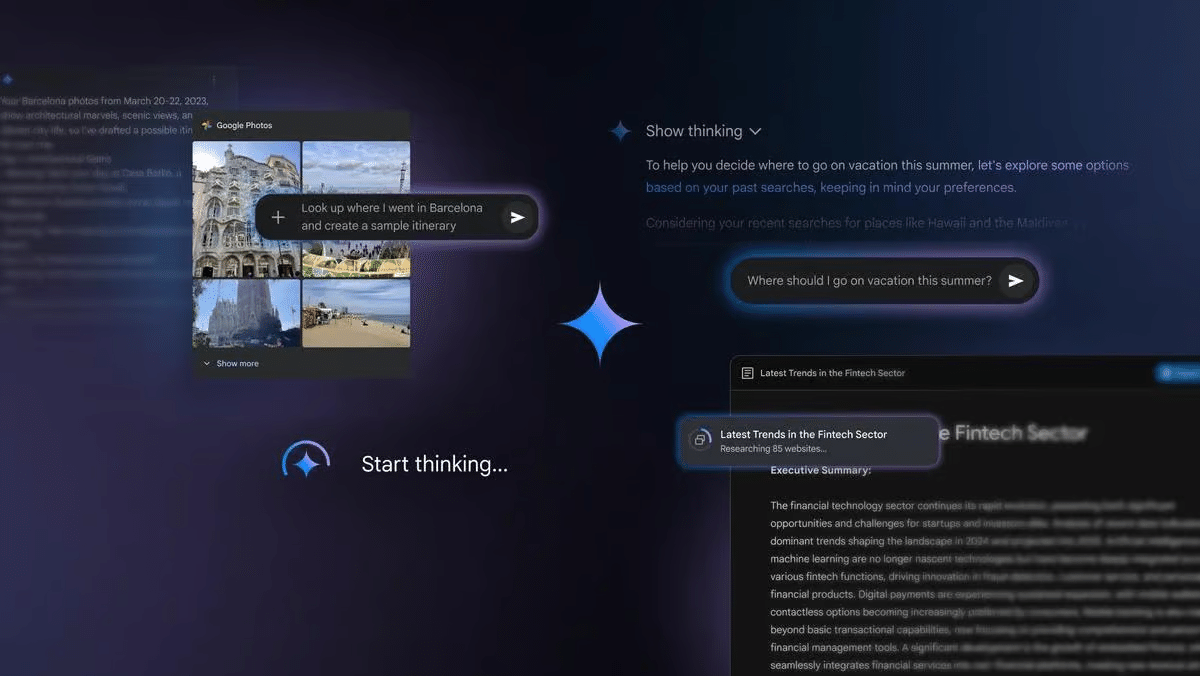
Geminiがマルチモーダル画像生成を無料開放
Alphabetが“Geminiイメージジェネレーター”を全ユーザーに提供開始
出典:Google
通常、テキスト → LLM → 画像 という変換で損失が発生しがちですが、Gemini 2.0 Flashは複数のモードをスムーズに行き来し、高速かつ高精度の生成を実現しました。
具体的に何ができる?
画像内の部分だけを編集(全部再生成せずに、一部のみ変更)
単語や文章を画像に直接埋め込み(雑誌の表紙に文字を自然に追加、など)
レシピ+写真やゲームキャラ+3Dモデルといった複合的なケースにも対応
サンプル事例:
雑誌カバーの値札を変える
クロワッサンにチョコレートソースをかける演出
画像スタイルの相互適用
さらにDeep Research機能が全ユーザーに解放され、**“Gems”**と呼ばれるプリセット機能(翻訳や食事プラン、数学コーチなど)を自由に活用可能。
アプリ連携や検索履歴の分析まで視野に入れた“パーソナル化”が進んでいます。
続きはこちらから → https://note.com/ai_clutch/n/n2d924d1d2588